unlock huawei e1732 idea net setter permanently




many people are having problem while connecting to internet with other sim cards
now you can connect by any sim card with default IDEA net Setter Dashboard using these steps
If your Modem is detecting sim cards and you are getting errors then do this
for XP
1 Control Panel -> Phone and Modem (found directly in control panel or in Printers and other hardware ) –> modem tab –> huawei mobile connect 3g modem (which is present on COM ) –> –> properties advance –> in extra initializing command use given commands and click OK
for windows 7
start menu -. type phone and modem — click on it—>modems –>huawei mobile connect 3g modem–properties–>change settings–>advance–>extra initialization command–>use given command
and if it ask for Country and area code then Country –India and Area
Code – 91 and leave other blank
commands are here
Aircel – AT+CGDCONT=1,”IP”,”aircelgprs”
Airtel – AT+CGDCONT=1,”IP”,”airtelgprs.com”
BSNL – AT+CGDCONT=1,”IP”,”bsnlnet”
Idea – AT+CGDCONT=1,”IP”,”internet”
Reliance – AT+CGDCONT=1,”IP”,”rcomnet”
Tata Docomo – AT+CGDCONT=1,”IP”,”tata.docomo.internet”
Videocon – AT+CGDCONT=1,”IP”,”vinternet.com”
Vodafone – AT+CGDCONT=1,”IP”,”www”
if you have any trouble doing this please comment here
a new way to unlock huawei e1732 idea netsetter permanently
many people had problems with unlocking idea netsetter huawei e1732. so here is a new method introduced by nill and it works 100%. first of all you must have patience doing this. because the process it bit long. and also you have to download some softwares. and while downloading the software you will have to disable your antivirus as the crack for the cdma workshop is considered a virus by many anti virus softwares. so these are the things that you should note while unlocking your huawei e1732 idea netsetter usb modem. and also you should not start your huawei e1732 dashboardso here is the step by step guide to unlocking huawei e1732 idea netsetter
- download the cdma workshop and save the cdma workshop v 2.7.0. you must disable antivirus before opening the cdma workshop
- download huawei e1732 downgrader
- insert a non idea sim to your huawei e1732 netsetter
- now you must find the common port to which your huawei e1732 modem is connected. you can do this by.
- Right click on your “My Computer” icon > Properties > Device Manager > Ports (COM & LPT) > HUAWEI Mobile Connect – 3G Application Interface (COM[The port number appear in your system])
- note down the com port number into which your huawei e1732 idea netsetter modem is connected
- Run “CDMA Workshop v2.7.0.exe”
- Select the Port that you noted from your Device Manager under the Port option in “COM Settings (AT mode)” under the “Main” tab.

- then click on connect and then click on read
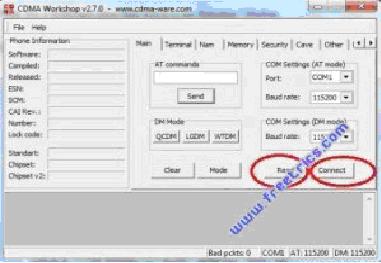
- Go to the “Security” tab > Type “000000” in the blank box under “SPC” > Click on “SPC” button > Click on “Send” with Default (nv_read) as SPC.

- Click on “Memory” tab > NV Items > Read > Now a “Conform” box will appear > Click “OK” > Now a “NV Items Backup” box will appear > In the box straight to “Last NV Item” type “9999” > Click “OK” > Save the file by giving a file name you like (Eg: E1732Unlock etc.)

- When the buffer reach “100%” your file is saved successfully > Now a “Information” box will appear > Click “OK” > Minimise “CDMA Workshop v2.7.0”
- Run “E1732 Downgrader” > accept the agreement > Next > Wait for a few seconds until the search for your modem finishes > (Don’t mark on “Auto remove the device after update”) Next > (Don’t remove your data card until the process is finished) > Start > At the end of “Downloading Programs…” you will get a “Update Failure!” error dialog box (DON’T WORRY & DON’T GET DISAPPOINTED) > Click “OK” > Click “Finish
- Restore “CDMA Workshop v2.7.0” > “Main” tab > Disconnect
- Unplug your Idea Netsetter (Modem) from your computer.
- Again Plug it to the Computer > Check the “Port” again from the “Device Manager”
- Go to “CDMA Workshop v2.7.0” select the Port that you noted from your Device Manager under the Port option in “COM Settings (AT mode)” under the “Main” tab as we did before > Click on “Connect” > “Memory” tab > NV Items > Click on “Write” > A “Confirm” box will appear > Click “OK” > “Open” dialog box will appear > Open the file that you saved before > When the buffer reach “100%” a “Information” dialog box appears with a success message > Click “OK” > “Main” tab > Disconnect
- Now close “CDMA Workshop v2.7.0” > A “Confirm” dialogue box will appear > Click “NO”
- Close everything > Enable your Antivirus
- That’s it. Your Idea Netsetter E1732 is unlocked successfully.
- Unplug Idea Netsetter (Modem) from your computer.
- Again Plug it to the Computer.
- Wait for Idea Netsetter to Start
- Put a SIM Card other than IDEA to the Netsetter / ModemIf it again shows “The SIM/USIM card not been detected or is invalid” (DON’T GET DISAPPOINTED) > Click “OK” > Wait for the SIM card to be detected > It will detect the SIM card and enjoy browsing with any other SIM.
- to make new mobile apn settings you can download huawei mobile partner. read and download mobile partner from this page
many people are having problem while connecting to internet with other sim cards
now you can connect by any sim card with default IDEA net Setter Dashboard using these steps
If your Modem is detecting sim cards and you are getting errors then do this
for XP
1 Control Panel -> Phone and Modem (found directly in control panel or in Printers and other hardware ) –> modem tab –> huawei mobile connect 3g modem (which is present on COM ) –> –> properties advance –> in extra initializing command use given commands and click OK
for windows 7
start menu -. type phone and modem — click on it—>modems –>huawei mobile connect 3g modem–properties–>change settings–>advance–>extra initialization command–>use given command
and if it ask for Country and area code then Country –
commands are here
Aircel – AT+CGDCONT=1,”IP”,”aircelgprs”
Airtel – AT+CGDCONT=1,”IP”,”airtelgprs.com”
BSNL – AT+CGDCONT=1,”IP”,”bsnlnet”
Idea – AT+CGDCONT=1,”IP”,”internet”
Reliance – AT+CGDCONT=1,”IP”,”rcomnet”
Tata Docomo – AT+CGDCONT=1,”IP”,”tata.docomo.internet”
Videocon – AT+CGDCONT=1,”IP”,”vinternet.com”
Vodafone – AT+CGDCONT=1,”IP”,”www”
if you have any trouble doing this please comment here
















